x_train=train.drop(columns=['Segmentation'])
x_test=test
y_train=train['Segmentation']
print(x_train.shape)
print(x_test.shape)
print(y_train.shape)
print(x_train.info())
print(x_test.info())
print(y_train.info())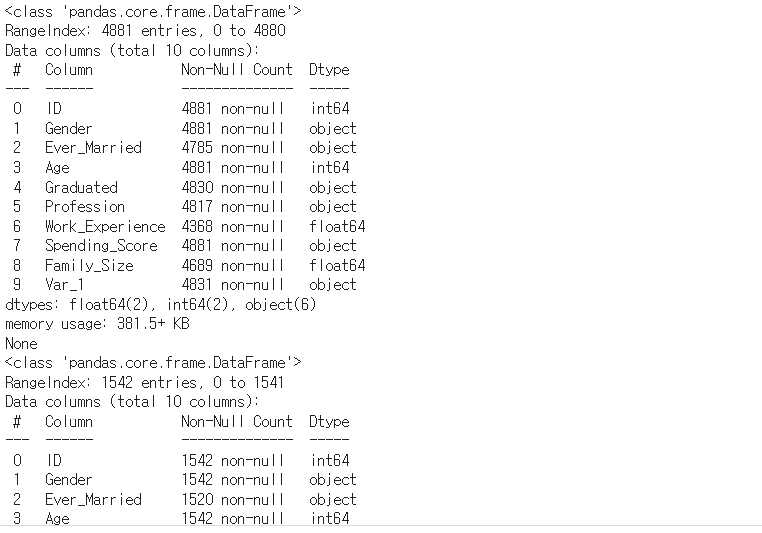
사진 설명을 입력하세요.
결측치가 엄청 많다 드디어 나왔구나 결측치 있는 데이터가!
print(x_train.describe())
print(y_train.describe())
print(x_test.describe())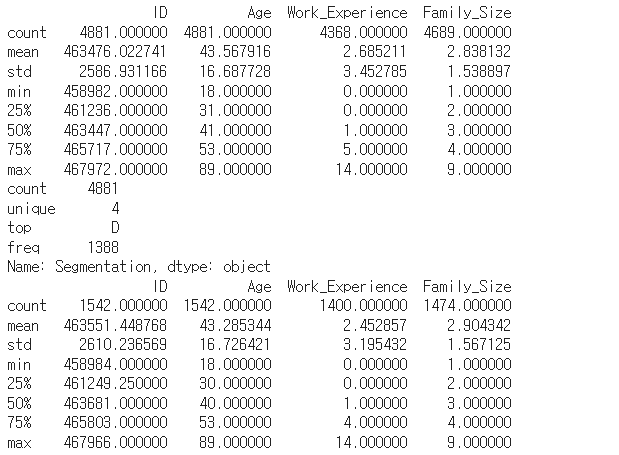
사진 설명을 입력하세요.
이상치값 있는지 확인해봤으나 없었음
print(x_train.isnull().sum())
print(x_test.isnull().sum())사진 설명을 입력하세요.
하지만 결측치값 엄청 많고...
# x_train : Ever_Married, Graduated, Profession, Work_Experience(수치), Family_Size(수치), Var_1 결측치
# x_test : Ever_Married, Graduated, Profession, Work_Experience, Family_Size, Var_1
x_train=x_train.drop(columns=['Work_Experience'])
x_test=x_test.drop(columns=['Work_Experience'])
family_median=x_train['Family_Size'].median()
ever_mode=x_train['Ever_Married'].mode()
graduated_mode=x_train['Graduated'].mode()
var_mode=x_train['Var_1'].mode()
profession_mode=x_train['Profession'].mode()
x_train['Family_Size']=x_train['Family_Size'].fillna(family_median)
x_train['Ever_Married']=x_train['Ever_Married'].fillna(ever_mode[0])
x_train['Graduated']=x_train['Graduated'].fillna(graduated_mode[0])
x_train['Var_1']=x_train['Var_1'].fillna(var_mode[0])
x_train['Profession']=x_train['Profession'].fillna(profession_mode[0])
x_test['Family_Size']=x_test['Family_Size'].fillna(family_median)
x_test['Ever_Married']=x_test['Ever_Married'].fillna(ever_mode[0])
x_test['Graduated']=x_test['Graduated'].fillna(graduated_mode[0])
x_test['Var_1']=x_test['Var_1'].fillna(var_mode[0])
x_test['Profession']=x_test['Profession'].fillna(profession_mode[0])** 주의사항 : train 데이터의 중앙값으로 test 데이터도 변경해줘야 함 **
# 연속형 변수 : 중앙값, 평균값
# df['변수명'].median()
# df['변수명'].mean()
# 범주형 변수 : 최빈값
# df['변수명'] = df['변수명'].fillna(대체할 값)## 중앙값 대체 예제 ##
med_age = x_train['age'].median()
x_train['age'] = x_train['age'].fillna(med_age)
x_test['age'] = x_test['age'].fillna(med_age) **주의사항: train 데이터의 최빈값의 [0]를 가져와야 함 **
ever_mode=x_train['Ever_Married'].mode()
x_test['Ever_Married']=x_test['Ever_Married'].fillna(ever_mode[0]) # 최빈값 [0] 주의아무튼 결측치 다 채워주고, 버릴 칼럼을 버렸음, work_experience를 대체해도 되지만 값이 커서 그냥 버렸다
이상치는 없으니 패스하고 변수 제거, 원핫 인코딩 해줘야함 (인코딩 사실 까먹어서 오류나서 다시 올라가서 함 ㅎㅎ..)
ID=x_test['ID'].copy()
x_train=x_train.drop(columns=['ID'])
x_test=x_test.drop(columns=['ID'])ID 칼럼은 필요없으니 드랍해주자
df = df.drop(columns = ['변수1','변수2'])
df = df.drop(['변수1','변수2'], axis=1) <필요없는 칼럼 제거하는 방법은 위와 같다>
x_train=pd.get_dummies(x_train)
x_test=pd.get_dummies(x_test)
print(x_train.info())
print(x_test.info())원핫 인코딩 해보고 x_train, x_test 칼럼 개수와 순서 비교했는데 일치해서 reindex가 필요 없음
from sklearn.model_selection import train_test_split
x_train,x_val,y_train,y_val=train_test_split(x_train,
y_train,
stratify=y_train,
test_size=0.2,
random_state=2024)
print(x_train.shape)
print(x_val.shape)
print(y_train.shape)
print(y_val.shape)분류분석 이니까 stratify 꼭 써주자!
from sklearn.ensemble import RandomForestClassifier
model=RandomForestClassifier(random_state=2024)
model.fit(x_train,y_train)y_pred=model.predict(x_val)
from sklearn.metrics import f1_score
f1=f1_score(y_val,y_pred, average='macro')
print(f1)**주의사항:y값이 다중분류니까 macro 잊지말고 쓰기**
y_result=model.predict(x_test)
result=pd.DataFrame({'ID':ID,'Segmentation':y_result})
result.to_csv('datafox',index=False)
pd.read_csv("datafox")끝!
'🏆 자격증, 어학' 카테고리의 다른 글
| [빅데이터 분석기사] 실기 2회 - drop (0) | 2024.08.20 |
|---|---|
| [빅데이터 분석기사] 실기 3회- 2유형 prob (0) | 2024.08.20 |
| [빅데이터 분석기사] 실기 5회 - 2유형 x_train과 x_test 개수가 다를때 reindex 사용 (0) | 2024.08.20 |
| [빅데이터 분석기사] 실기 6회 - 2유형 macro (0) | 2024.08.20 |
| [빅데이터 분석기사] 실기 7회 - 2유형 RandomForestRegressor (0) | 2024.08.20 |